高可用OpenStack(Queen版)集群
3.高可用配置(pacemaker&haproxy)
源自于网络-snowchuai汇总、整理
参考文档:
- Install-guide:https://docs.openstack.org/install-guide/
- OpenStack High Availability Guide:https://docs.openstack.org/ha-guide/index.html
- 理解Pacemaker:http://www.cnblogs.com/sammyliu/p/5025362.html
- Ceph: http://docs.ceph.com/docs/master/start/intro/
六.Pacemaker cluster stack集群
Openstack官网使用开源的pacemaker cluster stack做为集群高可用资源管理软件。
详细介绍:https://docs.openstack.org/ha-guide/controller-ha-pacemaker.html
1. 安装pacemaker
xxxxxxxxxx# 在全部控制节点安装相关服务,以controller01节点为例;# pacemaker:资源管理器(CRM),负责启动与停止服务,位于 HA 集群架构中资源管理、资源代理层# corosync:消息层组件(Messaging Layer),管理成员关系、消息与仲裁,为高可用环境中提供通讯服务,位于高可用集群架构的底层,为各节点(node)之间提供心跳信息;# resource-agents:资源代理,在节点上接收CRM的调度,对某一资源进行管理的工具,管理工具通常为脚本;# pcs:命令行工具集;# fence-agents:fencing 在一个节点不稳定或无答复时将其关闭,使其不会损坏集群的其它资源,其主要作用是消除脑裂[root@controller01 ~]# yum install pacemaker pcs corosync fence-agents resource-agents -y
2. 构建集群
xxxxxxxxxx# 启动pcs服务,在全部控制节点执行,以controller01节点为例[root@controller01 ~]# systemctl enable pcsd[root@controller01 ~]# systemctl start pcsd# 修改集群管理员hacluster(默认生成)密码,在全部控制节点执行,以controller01节点为例[root@controller01 ~]# echo pacemaker_pass | passwd --stdin hacluster

xxxxxxxxxx# 认证配置在任意节点操作,以controller01节点为例;# 节点认证,组建集群,需要采用上一步设置的password[root@controller01 ~]# pcs cluster auth controller01 controller02 controller03 -u hacluster -p pacemaker_pass --force

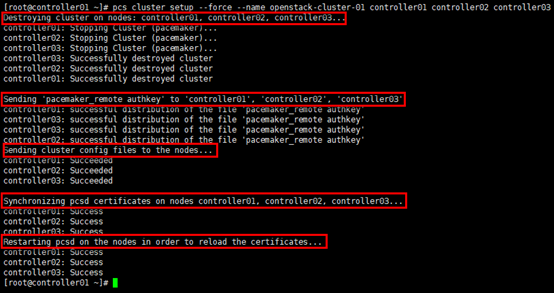
xxxxxxxxxx# 创建并命名集群,在任意节点操作,以controller01节点为例;# 生成配置文件:/etc/corosync/corosync.conf[root@controller01 ~]# pcs cluster setup --force --name openstack-cluster-01 controller01 controller02 controller03
3. 启动
xxxxxxxxxx# 启动集群,以controller01节点为例[root@controller01 ~]# pcs cluster start --all

xxxxxxxxxx# 设置集群开机启动[root@controller01 ~]# pcs cluster enable --all
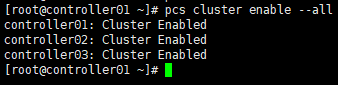
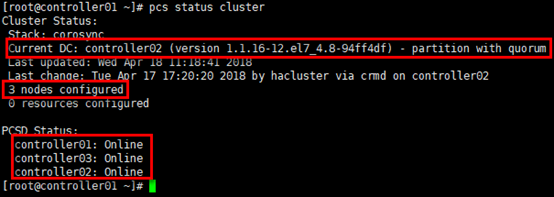
xxxxxxxxxx# 查看集群状态,也可使用” crm_mon -1”命令;# “DC”:Designated Controller;# 通过”cibadmin --query --scope nodes”可查看节点配置[root@controller01 ~]# pcs status cluster
xxxxxxxxxx# 查看corosync状态;# “corosync”表示一种底层状态等信息的同步方式[root@controller01 ~]# pcs status corosync
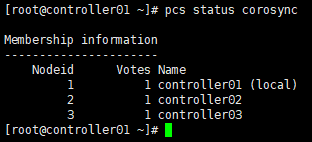
xxxxxxxxxx# 查看节点;# 或:corosync-cmapctl runtime.totem.pg.mrp.srp.members[root@controller01 ~]# corosync-cmapctl | grep members
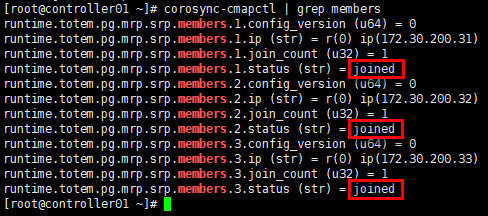
xxxxxxxxxx# 查看集群资源[root@controller01 ~]# pcs resource
或通过web访问任意控制节点:https://172.30.200.31:2224,
账号/密码(即构建集群时生成的密码):hacluster/pacemaker_pass
4. 设置属性
xxxxxxxxxx# 在任意控制节点设置属性即可,以controller01节点为例;# 设置合适的输入处理历史记录及策略引擎生成的错误与警告,在troulbshoot时有用[root@controller01 ~]# pcs property set pe-warn-series-max=1000 \pe-input-series-max=1000 \pe-error-series-max=1000# pacemaker基于时间驱动的方式进行状态处理,” cluster-recheck-interval”默认定义某些pacemaker操作发生的事件间隔为15min,建议设置为5min或3min[root@controller01 ~]# pcs property set cluster-recheck-interval=5# corosync默认启用stonith,但stonith机制(通过ipmi或ssh关闭节点)并没有配置相应的stonith设备(通过“crm_verify -L -V”验证配置是否正确,没有输出即正确),此时pacemaker将拒绝启动任何资源;# 在生产环境可根据情况灵活调整,验证环境下可关闭[root@controller01 ~]# pcs property set stonith-enabled=false# 默认当有半数以上节点在线时,集群认为自己拥有法定人数,是“合法”的,满足公式:total_nodes < 2 * active_nodes;# 以3个节点的集群计算,当故障2个节点时,集群状态不满足上述公式,此时集群即非法;当集群只有2个节点时,故障1个节点集群即非法,所谓的”双节点集群”就没有意义;# 在实际生产环境中,做2节点集群,无法仲裁时,可选择忽略;做3节点集群,可根据对集群节点的高可用阀值灵活设置[root@controller01 ~]# pcs property set no-quorum-policy=ignore# v2的heartbeat为了支持多节点集群,提供了一种积分策略来控制各个资源在集群中各节点之间的切换策略;通过计算出各节点的的总分数,得分最高者将成为active状态来管理某个(或某组)资源;# 默认每一个资源的初始分数(取全局参数default-resource-stickiness,通过"pcs property list --all"查看)是0,同时每一个资源在每次失败之后减掉的分数(取全局参数default-resource-failure-stickiness)也是0,此时一个资源不论失败多少次,heartbeat都只是执行restart操作,不会进行节点切换;# 如果针对某一个资源设置初始分数”resource-stickiness“或"resource-failure-stickiness",则取单独设置的资源分数;# 一般来说,resource-stickiness的值都是正数,resource-failure-stickiness的值都是负数;有一个特殊值是正无穷大(INFINITY)和负无穷大(-INFINITY),即"永远不切换"与"只要失败必须切换",是用来满足极端规则的简单配置项;# 如果节点的分数为负,该节点在任何情况下都不会接管资源(冷备节点);如果某节点的分数大于当前运行该资源的节点的分数,heartbeat会做出切换动作,现在运行该资源的节点将释 放资源,分数高出的节点将接管该资源# pcs property list 只可查看修改后的属性值,参数”--all”可查看含默认值的全部属性值;# 也可查看/var/lib/pacemaker/cib/cib.xml文件,或”pcs cluster cib”,或“cibadmin --query --scope crm_config”查看属性设置,” cibadmin --query --scope resources”查看资源配置[root@controller01 ~]# pcs property list

5. 配置vip
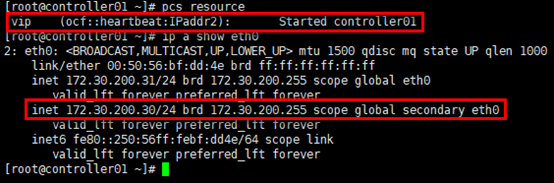
xxxxxxxxxx# 在任意控制节点设置vip(resource_id属性)即可,命名即为“vip”;# ocf(standard属性):资源代理(resource agent)的一种,另有systemd,lsb,service等;# heartbeat:资源脚本的提供者(provider属性),ocf规范允许多个供应商提供同一资源代理,大多数ocf规范提供的资源代理都使用heartbeat作为provider;# IPaddr2:资源代理的名称(type属性),IPaddr2便是资源的type;# 通过定义资源属性(standard:provider:type),定位”vip”资源对应的ra脚本位置;# centos系统中,符合ocf规范的ra脚本位于/usr/lib/ocf/resource.d/目录,目录下存放了全部的provider,每个provider目录下有多个type;# op:表示Operations[root@controller01 ~]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.30.200.30 cidr_netmask=24 op monitor interval=30s# 查看集群资源[root@controller01 ~]# pcs resourceprpr# 通过”pcs resouce”查询,vip资源在controller01节点;# 通过”ip a show”可查看vip[root@controller01 ~]# ip a show eth0
6. High availability management
通过web访问任意控制节点:https://172.30.200.31:2224
账号/密码(即构建集群时生成的密码):hacluster/pacemaker_pass
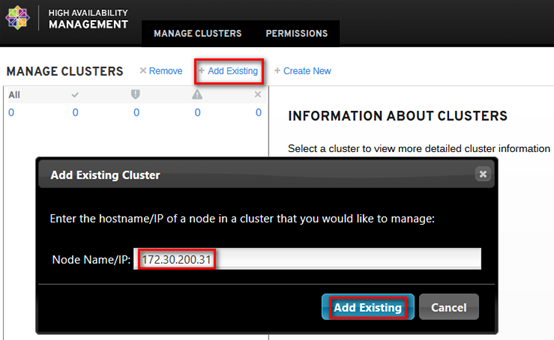
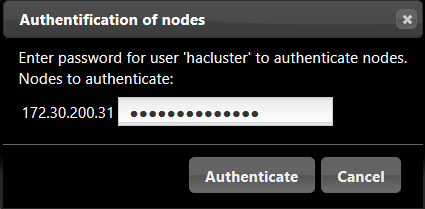
虽然以cli的方式设置了集群,但web界面默认并不显示,手动添加集群;实际操作只需要添加已组建集群的任意节点即可,如下:
xxxxxxxxxx# 如果api区分admin/internal/public接口,对客户端只开放public接口,通常设置两个vip,如命名为:vip_management与vip_public;# 建议是将vip_management与vip_public约束在1个节点# [root@controller01 ~]# pcs constraint colocation add vip_management with vip_public
七.Haproxy
1. 安装haproxy
xxxxxxxxxx# 在全部控制节点安装haproxy,以controller01节点为例;# 如果需要安装最新版本,可参考:http://www.cnblogs.com/netonline/p/7593762.html[root@controller01 ~]# yum install haproxy -y
2. 配置haproxy.cfg
xxxxxxxxxx# 在全部控制节点配置haproxy.cfg,以controller01节点为例;# haproxy依靠rsyslog输出日志,是否输出日志根据实际情况设定;# 备份原haproxy.cfg文件[root@controller01 ~]# cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak# 集群的haproxy文件,涉及服务较多,这里针对涉及到的openstack服务,一次性设置完成,如下:[root@controller01 ~]# grep -v ^# /etc/haproxy/haproxy.cfgglobalchroot /var/lib/haproxydaemongroup haproxyuser haproxymaxconn 4000pidfile /var/run/haproxy.piddefaultslog globalmaxconn 4000option redispatchretries 3timeout http-request 10stimeout queue 1mtimeout connect 10stimeout client 1mtimeout server 1mtimeout check 10s# haproxy监控页listen statsbind 0.0.0.0:1080mode httpstats enablestats uri /stats realm OpenStack\ Haproxystats auth admin:adminstats refresh 30sstats show-nodestats show-legendsstats hide-version# horizon服务listen dashboard_clusterbind 172.30.200.30:80balance sourceoption tcpkaoption httpchkoption tcplogserver controller01 172.30.200.31:80 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:80 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:80 check inter 2000 rise 2 fall 5# mariadb服务;# 设置controller01节点为master,controller02/03节点为backup,一主多备的架构可规避数据不一致性;# 另外官方示例为检测9200(心跳)端口,测试在mariadb服务宕机的情况下,虽然”/usr/bin/clustercheck”脚本已探测不到服务,但受xinetd控制的9200端口依然正常,导致haproxy始终将请求转发到mariadb服务宕机的节点,暂时修改为监听3306端口listen galera_clusterbind 172.30.200.30:3306balance sourcemode tcpserver controller01 172.30.200.31:3306 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:3306 backup check inter 2000 rise 2 fall 5server controller03 172.30.200.33:3306 backup check inter 2000 rise 2 fall 5# 为rabbirmq提供ha集群访问端口,供openstack各服务访问;# 如果openstack各服务直接连接rabbitmq集群,这里可不设置rabbitmq的负载均衡listen rabbitmq_clusterbind 172.30.200.30:5673mode tcpoption tcpkabalance roundrobintimeout client 3htimeout server 3hoption clitcpkaserver controller01 172.30.200.31:5672 check inter 10s rise 2 fall 5server controller02 172.30.200.32:5672 check inter 10s rise 2 fall 5server controller03 172.30.200.33:5672 check inter 10s rise 2 fall 5# glance_api服务listen glance_api_clusterbind 172.30.200.30:9292balance sourceoption tcpkaoption httpchkoption tcplogserver controller01 172.30.200.31:9292 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:9292 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:9292 check inter 2000 rise 2 fall 5# glance_registry服务listen glance_registry_clusterbind 172.30.200.30:9191balance sourceoption tcpkaoption tcplogserver controller01 172.30.200.31:9191 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:9191 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:9191 check inter 2000 rise 2 fall 5# keystone_admin_internal_api服务listen keystone_admin_clusterbind 172.30.200.30:35357balance sourceoption tcpkaoption httpchkoption tcplogserver controller01 172.30.200.31:35357 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:35357 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:35357 check inter 2000 rise 2 fall 5# keystone_public _api服务listen keystone_public_clusterbind 172.30.200.30:5000balance sourceoption tcpkaoption httpchkoption tcplogserver controller01 172.30.200.31:5000 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:5000 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:5000 check inter 2000 rise 2 fall 5# 兼容aws ec2-apilisten nova_ec2_api_clusterbind 172.30.200.30:8773balance sourceoption tcpkaoption tcplogserver controller01 172.30.200.31:8773 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:8773 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:8773 check inter 2000 rise 2 fall 5listen nova_compute_api_clusterbind 172.30.200.30:8774balance sourceoption tcpkaoption httpchkoption tcplogserver controller01 172.30.200.31:8774 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:8774 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:8774 check inter 2000 rise 2 fall 5listen nova_placement_clusterbind 172.30.200.30:8778balance sourceoption tcpkaoption tcplogserver controller01 172.30.200.31:8778 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:8778 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:8778 check inter 2000 rise 2 fall 5listen nova_metadata_api_clusterbind 172.30.200.30:8775balance sourceoption tcpkaoption tcplogserver controller01 172.30.200.31:8775 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:8775 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:8775 check inter 2000 rise 2 fall 5listen nova_vncproxy_clusterbind 172.30.200.30:6080balance sourceoption tcpkaoption tcplogserver controller01 172.30.200.31:6080 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:6080 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:6080 check inter 2000 rise 2 fall 5listen neutron_api_clusterbind 172.30.200.30:9696balance sourceoption tcpkaoption httpchkoption tcplogserver controller01 172.30.200.31:9696 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:9696 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:9696 check inter 2000 rise 2 fall 5listen cinder_api_clusterbind 172.30.200.30:8776balance sourceoption tcpkaoption httpchkoption tcplogserver controller01 172.30.200.31:8776 check inter 2000 rise 2 fall 5server controller02 172.30.200.32:8776 check inter 2000 rise 2 fall 5server controller03 172.30.200.33:8776 check inter 2000 rise 2 fall 5
3. 配置内核参数
xxxxxxxxxx# 全部控制节点修改内核参数,以controller01节点为例;# net.ipv4.ip_nonlocal_bind:是否允许no-local ip绑定,关系到haproxy实例与vip能否绑定并切换;# net.ipv4.ip_forward:是否允许转发[root@controller01 ~]# echo "net.ipv4.ip_nonlocal_bind = 1" >>/etc/sysctl.conf[root@controller01 ~]# echo "net.ipv4.ip_forward = 1" >>/etc/sysctl.conf[root@controller01 ~]# sysctl -p
4. 启动
xxxxxxxxxx# 开机启动是否设置可自行选择,利用pacemaker设置haproxy相关资源后,pacemaker可控制各节点haproxy服务是否启动# [root@controller01 ~]# systemctl enable haproxy[root@controller01 ~]# systemctl restart haproxy[root@controller01 ~]# systemctl status haproxy
5. 设置pcs资源
xxxxxxxxxx# 任意控制节点操作即可,以controller01节点为例;# 添加资源lb-haproxy-clone[root@controller01 ~]# pcs resource create lb-haproxy systemd:haproxy --clone[root@controller01 ~]# pcs resource

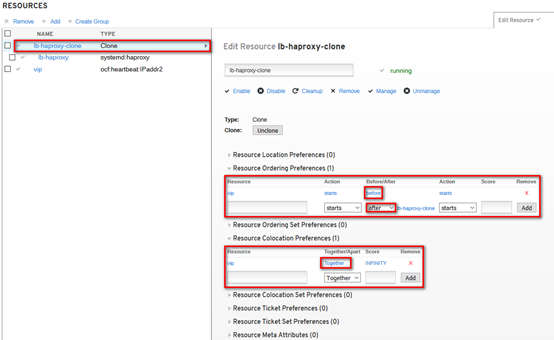
xxxxxxxxxx# 设置资源启动顺序,先vip再lb-haproxy-clone;# 通过“cibadmin --query --scope constraints”可查看资源约束配置[root@controller01 ~]# pcs constraint order start vip then lb-haproxy-clone kind=Optional

xxxxxxxxxx# 官方建议设置vip运行在haproxy active的节点,通过绑定lb-haproxy-clone与vip服务,将两种资源约束在1个节点;# 约束后,从资源角度看,其余暂时没有获得vip的节点的haproxy会被pcs关闭[root@controller01 ~]# pcs constraint colocation add lb-haproxy-clone with vip[root@controller01 ~]# pcs resource
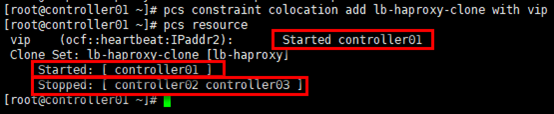
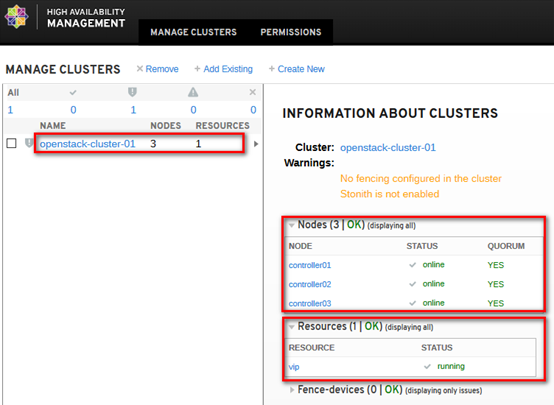
通过high availability management查看资源相关的设置,如下: